Trails A and B: Clinician's Guide & Digital Trends
Apr 16, 2026

A patient sits down in your clinic and says, “I’m just foggy lately.” They mention misplaced keys, slower reading, and occasional word-finding trouble. Their neurological exam is largely unremarkable. Their mood may be low, or perhaps they’re worried. You need something fast, structured, and clinically meaningful.
That’s where trails a and b still earn their place.
Used well, the Trail Making Test is more than a quick screening exercise. It helps you translate vague complaints into observable behaviour. You see visual scanning, pace, error monitoring, mental flexibility, and how a person handles pressure when the rule changes. In a few minutes, you often learn whether the problem looks more like slowed throughput, executive disorganisation, motor interference, or an anxious but intact performance style.
Junior clinicians often underestimate it because the materials look simple. A page of circles and a pencil don't look complex. But the simplicity is deceptive. The value of trails a and b lies in disciplined administration and thoughtful interpretation.
Introducing the Trail Making Test in Clinical Practice
A referral arrives late in the morning clinic. The patient is older, worried, and vague in a familiar way. “My memory is slipping.” The family reports slower thinking, more frustration, and trouble juggling everyday tasks. At that point, you are not just asking whether cognition has changed. You are asking what kind of change you are seeing, and whether it reflects mood, motor slowing, inefficient attention, medication effects, or an emerging neurocognitive disorder.

The Trail Making Test helps answer that question quickly. In Part A, the patient connects numbers in order. In Part B, they alternate between numbers and letters. The materials are simple, but the task works like a brief stress test for cognitive efficiency. It lets you watch how a person searches, sequences, shifts set, and recovers from mistakes under time pressure.
Clinicians have kept using trails a and b for decades because the test answers practical bedside questions. Is the person slow across the board, or does performance break down when the rule changes? Can they keep an organised search pattern, or do they lose the thread once two sequences must be held in mind at once? Those are questions you can use immediately in case formulation.
Its long history also matters. The Trail Making Test grew out of military neuropsychological screening in the mid-20th century and was later adapted for broader clinical use. That staying power reflects a simple truth from practice. A task does not need elaborate materials to reveal meaningful differences in how a patient manages attention and control.
A junior clinician will often focus on completion time alone. That is a start, not the whole interpretation.
What makes this test clinically useful is the combination of score and process. A patient who moves slowly but methodically raises a different set of questions than one who moves quickly, loses place, and needs repeated correction. Another may pause at every transition in Part B, which often points you toward inefficiency in set shifting rather than a primary memory problem. If you need a quick refresher on the speed component, this guide to processing speed in cognitive assessment gives helpful context.
That same logic explains why digital versions deserve attention. The classic paper form remains valuable, but it also has built-in limits. Timing can be coarse, error patterns may be captured inconsistently, and subtle behaviours between start and finish are easy to miss in a busy clinic. Digital platforms such as Orange Neurosciences preserve the core clinical challenge of trails a and b while improving standardisation and capturing richer performance data. In practice, that means the test can stay familiar to clinicians while becoming more precise, more consistent, and easier to integrate into modern assessment workflows.
Deconstructing Trails A and B Cognitive Demands
Part A and Part B ask for different kinds of mental work. That distinction matters at the bedside, because a patient can look intact on one and struggle on the other for reasons that are clinically informative.
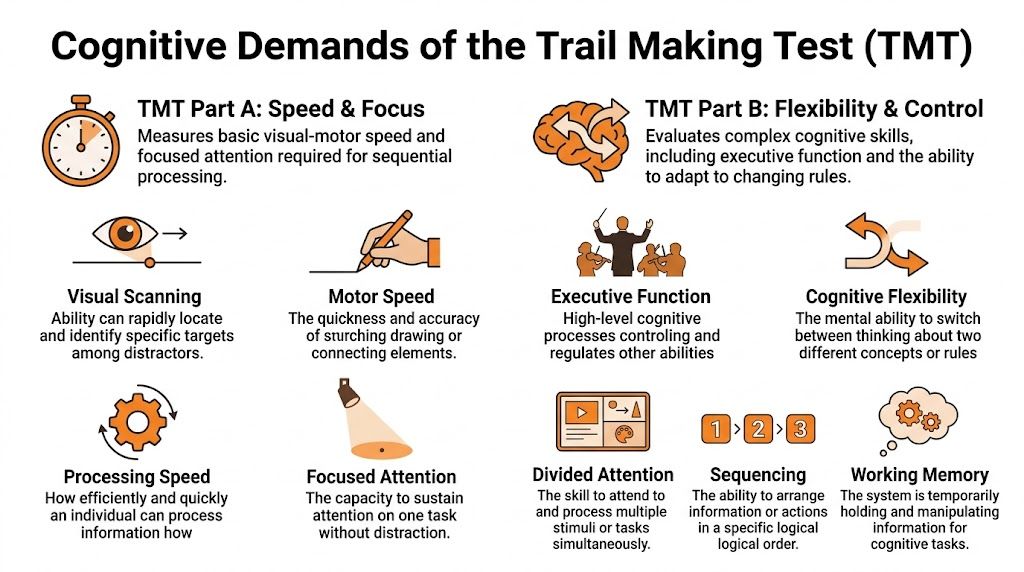
A useful way to teach this is to start with the rule structure. In Part A, the patient follows one sequence. In Part B, the patient must alternate between two sequences while keeping the switching rule active. On paper, that looks like a small increase in difficulty. In practice, it often changes the whole task.
What Part A is really measuring
Part A usually appears simple to patients and trainees. Simplicity can be deceptive.
The patient connects numbers in ascending order, but successful performance still depends on several systems working together:
Visual scanning. Finding the next target without repeatedly searching the same area.
Sustained attention. Staying engaged from start to finish.
Psychomotor speed. Translating what is seen into a quick motor response.
Sequencing. Holding the basic rule and carrying it through consistently.
Clinically, Part A gives you a baseline for how efficiently the patient can process a straightforward visual-motor task. If performance is slow, the next question is not “Are they impaired?” The better question is “Where is the bottleneck?” Sometimes the pace is limited by slowed output. Sometimes by poor scanning. Sometimes by hesitancy, anxiety, or motor weakness. For a concise refresher on that speed component, see this guide to processing speed in cognitive assessment.
Why Part B places a different load on the patient
Part B keeps the same visual search and motor demands, then adds control demands on top of them. The patient must connect 1 to A to 2 to B and continue alternating correctly. That means they are not only finding the next target. They are also monitoring the rule, suppressing the wrong next response, and shifting set after each connection.
In clinic, this is often where the process becomes more revealing than the final time. A patient with intact basic speed may stall at each number-letter transition, as if they must restart the rule every few seconds. Another may move quickly but drift into a numbers-only pattern. Those are different failure modes. The first pattern often suggests inefficient set shifting. The second raises concern about inhibitory control and self-monitoring.
A junior clinician may label both performances “slow on B.” That loses the part that matters.
The teaching point that improves interpretation
Part B should not be described as merely harder. It is more controlled, more fragile, and more dependent on executive organisation.
What changes from A to B is the need to coordinate multiple operations at once:
keep two ordered sequences active
alternate between them without losing place
inhibit the overlearned tendency to continue along one track
update the rule after every response
maintain visual search under higher mental load
A practical comparison helps here. Part A is closer to driving on a clear road with one destination in mind. Part B is closer to driving while following alternating directions at every turn. The motor act is still steering, but the control demands are clearly higher.
That is also where digital versions begin to add clinical value without changing the core construct. The paper test shows whether the patient reaches the endpoint and how long it takes. A digital platform such as Orange Neurosciences can preserve the familiar alternation challenge while capturing pauses, hesitation points, correction patterns, and within-task variability with more consistency. For clinicians, that helps bridge an old strength of neuropsychology, careful observation, with a newer strength, finer-grained measurement.
Practical rule: Interpret Part B in relation to Part A, then ask what extra burden the alternation rule created for this specific patient.
That habit protects against a common interpretive error. Slow Part B performance can reflect executive inefficiency, but it can also reflect a patient who was already slowed by visual search, motor output, or general processing speed on Part A. The comparison is what turns a raw score into a useful clinical inference.
A Practical Guide to Test Administration
Good administration looks boring. That’s a compliment. The patient should receive a standardised task, not your improvisation.
Before the pencil touches the page
Set up the environment first. Reduce noise. Make sure the patient can see comfortably. Check whether they have their usual glasses or hearing support if needed. Position the page squarely in front of them and ensure the writing surface is stable.
Then decide what might interfere before you start. Hand weakness, tremor, dominant-hand injury, poor literacy, unfamiliarity with the Roman alphabet, and marked anxiety can all affect what follows.
Delivering instructions cleanly
Give the instructions clearly and the same way each time. Avoid adding coaching language such as “take your time” or “go as fast as you can without mistakes” unless that’s part of your standard procedure. Mixed messages change performance.
A useful discipline is to practise your wording until you can give it naturally and consistently. If you’re training staff across tasks, it helps to compare your approach with other standardised instruments. This guide to instructions for the MoCA is a good reminder that small wording changes can alter validity.
What to do with errors
Errors are not just scoring nuisances. They are data.
If the patient makes an error, stop them at the point of deviation and direct them back to the last correct item according to your standard protocol. Don’t lecture. Don’t explain the whole task again unless the administration rules require it. Watch what happens next.
A few examples matter clinically:
Self-correction before prompting often suggests preserved monitoring.
Repeated same-rule errors may indicate poor set maintenance.
Impulsive line drawing with minimal checking can point to weak inhibitory control.
Long freezes after correction may reflect overload, anxiety, or inefficient recovery.
Common mistakes to avoid
Timing errors
Start timing at the correct moment. Not during your final instruction. Not after the first line is drawn. Be consistent.
Overhelping
Many new clinicians rescue too quickly. A patient who hesitates may still solve the problem independently. If you intervene too early, you erase the behaviour you came to observe.
Ambiguous feedback
Avoid comments like “good”, “that’s fine”, or “almost”. Even mild reassurance can cue the patient.
If your administration style varies from patient to patient, your comparisons become less trustworthy.
Missing behavioural notes
Write down more than the final time. Note search strategy, visible frustration, verbal self-talk, pen lifts, and whether corrections were spontaneous or examiner-driven. Those notes often become the most useful part of the record.
From Raw Scores to Clinical Insights
A completion time is only the start. Interpreting trails a and b well means asking what the score means for this person, with their age, education, language background, motor status, and clinical question.
Start with norms, not intuition
Normative data were developed from 911 community-dwelling individuals aged 18 to 89 years, stratified across 11 age groups and 2 education levels, in the Archives of Clinical Neuropsychology study on Trail Making Test normative standards. That’s why “this seems slow to me” isn’t enough.
Age matters. Education matters. Gender did not show an effect in the data described in the earlier literature review, but age and education clearly shape performance. So don’t compare a retired engineer in their late eighties to a younger university graduate in your mental shorthand and call that interpretation.
Average performance is not the same as impairment
This is the point that often surprises trainees. For healthy adults, average completion times are about 29 seconds for TMT-A and 75 seconds for TMT-B, but deficiency cut-offs are much higher at more than 78 seconds for Part A and more than 273 seconds for Part B, based on the age- and education-stratified norms reported in Archives of Clinical Neuropsychology’s article on TMT scoring thresholds and discontinuation limits.
That gap tells you two things:
Part B tolerates a wide range of slower-but-still-meaningful performance.
Crossing into deficiency is not just “a bit slower than average”.
In other words, don’t pathologise every slow Trail B. A patient can be below average without meeting an impairment threshold.
A quick reference table
Use this table as a teaching aid, not as a substitute for full normative interpretation.
Measure | TMT-A | TMT-B | B/A Ratio Mean |
|---|---|---|---|
Healthy adult average | 29 s | 75 s | 75/29 |
Deficiency threshold | >78 s | >273 s | interpret clinically |
The ratio row is intentionally not turned into a new rounded statistic. When teaching, I prefer to show the relationship rather than invent precision the source didn’t provide.
Why derived scores matter
Raw Trail B time can mislead you. A patient with slow visuomotor speed may produce a slow B without disproportionate executive dysfunction. That’s where comparison metrics help.
The B/A ratio
The B/A ratio is often more informative than raw B alone because it adjusts B in light of the patient’s own baseline speed. If A is already slow, a slower B may be less alarming than it first appears. If A is reasonably efficient but B rises sharply, the executive cost stands out more clearly.
That’s why many clinicians treat the ratio as the cleaner lens on set-shifting and organisation, especially when motor speed is variable. It doesn’t replace judgement. It sharpens it.
The B minus A difference
The B-A difference can also be useful, particularly when you want a simple sense of how much extra burden the switching demand adds. But remember what it does poorly. It doesn’t control for baseline speed as neatly as the ratio.
Practical interpretation examples
Consider two patients.
Patient one is slow on both A and B. Their scanning is plodding. Their line production is careful. Errors are few. This pattern suggests broad slowing before you jump to a focal executive conclusion.
Patient two is acceptable on A, then becomes disorganised on B. They repeatedly continue the numeric sequence and need redirection. That pattern points much more strongly toward executive inefficiency.
A final point for clinicians who track change over time. Repeated testing is only useful if the measure itself is dependable. When you think about longitudinal interpretation, it helps to review broader issues in test-retest reliability in cognitive assessment.
A useful note in the chart is not “Trail B impaired”. It’s “Trail B disproportionately affected relative to Trail A, with repeated set-loss errors and limited spontaneous correction.”
That sentence helps the next clinician.
Applying TMT Patterns in Differential Diagnosis
A common clinic moment goes like this. You finish Trails A and think, "slow, but workable." Then Trails B begins, and the whole task changes shape. The patient can see the page. They can hold the pencil. Yet the rule slips away the moment two sequences must be coordinated. That shift is often more informative than the raw completion time.

Trails A and B support differential diagnosis by showing how a person manages speed, visual search, sequencing, and cognitive control under changing task demands. A single score rarely answers the referral question. The pattern across both parts, plus the error style, usually does.
When both parts are slow
Some patients are slow from the first line onward. Their scanning is effortful, their motor output is measured, and both parts take longer than expected without a dramatic gap between them. In practice, this pattern often fits broad inefficiency rather than a clean, focal executive problem.
You might see it in subcortical change, vascular burden, medication effects, fatigue, low initiation, or depression. The clinical logic is similar to watching someone drive slowly on every type of road. If city streets and highway ramps are both equally cautious, the issue may be general speed or confidence rather than difficulty with one specific manoeuvre.
Earlier in the article, we noted that comparing B to A can help separate baseline slowness from the added cost of switching. Used carefully, that comparison keeps you from overcalling executive dysfunction when the patient is globally slowed.
When A is relatively preserved but B breaks down
This pattern deserves close attention. A is acceptable. The patient follows the sequence, keeps visual place, and maintains momentum. Then B introduces a second rule, and performance becomes disorganised.
The most telling sign is often not the final time. It is the way the patient fails. They continue with numbers only, pause and rehearse the rule aloud, skip letters, or need repeated prompts to re-establish the alternation. A works like a straight hallway. B works like a hallway with alternating doors that must be opened in the correct order. Patients with executive weakness often do fine in the straight hallway and lose control once the rule has to be updated on each step.
That pattern raises concern for frontal-executive inefficiency, but context still matters. Delirium, acute stress, poor sleep, and low frustration tolerance can all produce a similar behavioural picture in the moment.
Short clinical vignettes
A frontal-executive presentation
A patient completes A with only mild slowing. On B, they repeatedly revert to the numeric sequence despite correction. What stands out is the limited spontaneous self-monitoring. They do not catch the set loss quickly, and the same error returns. That repetition points more strongly to impaired cognitive control than to simple caution or reduced motor speed.
Depression versus neurodegenerative concern
Another patient is slow on both parts, apologises frequently, and seems to lose pace after each small stumble. With encouragement, performance improves somewhat, and the rule itself remains intact. In this case, the behaviour around the task matters. Low confidence, reduced initiation, and variable effort can distort the score without producing the classic set-shifting failure pattern.
Developmental or attentional difficulties
A younger patient rushes through A and treats speed as the goal. On B, the same impulsive style creates place-loss and sequencing errors because they do not pause long enough to maintain the alternating rule. This can look "executive" at first glance, but the mechanism is different. The problem is poorly regulated pace and inconsistent working attention, not necessarily the same syndrome you would infer in a progressive neurocognitive disorder.
What to pair it with
Trail patterns become more useful when you place them beside memory, language, orientation, daily functioning, and the clinical history that brought the patient to you. If the referral question is possible dementia, the trail result should sit within a broader framework of bedside and office measures. A review of cognitive screening tests used for dementia is a helpful reminder that no single task should carry the whole interpretation.
The paper version of TMT still has diagnostic value because it exposes these patterns clearly and quickly. Its limits are familiar to any clinician who has scored enough protocols. Timing can be coarse, observations may be inconsistently documented, and subtle process data often disappear once the page is filed away. Digital platforms such as Orange Neurosciences aim to preserve the core logic of Trails while capturing the kind of trial-level behaviour clinicians already try to notice in real time, including pauses, hesitations, error correction, and performance change across repeated assessments. That does not replace clinical judgement. It gives that judgement a cleaner behavioural record.
Ask what cognitive operation failed, when it failed, and how the patient responded to the failure. That question usually leads to a better differential than the total time alone.
Navigating Common Pitfalls and Patient Factors
A slow score doesn’t always mean executive dysfunction. In fact, one of the most important habits in neuropsychology is learning when not to overinterpret trails a and b.
Motor demand is not a side issue
Part B isn’t only cognitively harder. It is also mechanically more demanding. The drawn line length in TMT-B is 32% longer for adults than in TMT-A, according to the technical analysis published in Perceptual and Motor Skills on the structural motor difference between Trails A and B.
That matters. A patient with tremor, arthritis, weakness, poor dexterity, or post-stroke motor change may look cognitively worse on B partly because the task requires more physical output on the page.
Clinical example
A patient with Parkinsonian features may understand the rule perfectly but produce a very slow and effortful written path. If you treat that as a clean measure of executive switching, you risk attributing motor limitation to cognition.
Education and ageing shape expectations
Older adults often slow down on both parts. People with less formal education may also perform differently, particularly when the task taxes overlearned sequencing and test familiarity. That’s why the normative framework matters so much.
You are not measuring cognition in the abstract. You’re measuring this person, in this format, with this educational and cultural history.
Language and alphabet familiarity
Part B assumes comfort with alternating numbers and letters in the testing language. For some multilingual patients, the switching rule itself may be less automatic than it is for native English speakers. That doesn’t make the result invalid, but it does change what the score may represent.
A practical checklist before you interpret
Check motor status. Was the hand steady? Was line production effortful?
Check literacy and alphabet fluency. Could the patient move comfortably through letter order?
Check sensory factors. Vision and hearing problems can alter pace and confidence.
Check emotional tone. Anxiety can create hesitations that look cognitive.
Check the error style. Organised but slow is different from impulsive and disorganised.
The more a test depends on drawing, scanning, and overlearned symbols, the more carefully you must separate cognitive failure from format burden.
That distinction protects patients from lazy conclusions.
The Future Is Digital Augmenting Trail Making
The classic paper version still has value. It’s portable, familiar, and clinically rich. But it also has limitations. Motor confounds can distort interpretation. Manual timing introduces small inconsistencies. Static formats give you only the final score unless the examiner takes detailed notes.
Digital trail-making tools offer a practical evolution rather than a rejection of the original model.
When response capture happens through tapping or clicking rather than drawing long connecting lines, you can reduce part of the motor burden that complicates paper interpretation. Automated timing also improves precision. More importantly, digital systems can preserve trial-level information that paper testing usually loses, such as pauses, hesitations, error sequences, and recovery after correction.
There is also a population issue. A significant gap remains in normative data for diverse groups, and a future-dated report notes that AI-enhanced digital TMT variants can reduce errors by up to 22% in some populations, though public norms are still lacking, according to the cited discussion of diversity gaps and emerging digital approaches in the 2026 evidence summary on TMT limitations and digital adaptation. That should be read as an emerging direction, not settled clinical consensus.
If you’re exploring how digital cognitive workflows can complement traditional testing, this guide to online cognitive assessment is a useful place to start. The best systems don’t discard the logic of trails a and b. They keep the core challenge and improve the measurement.
If you want to bring trail-making and broader cognitive assessment into a more precise, scalable workflow, explore Orange Neurosciences. Its platform supports rapid, structured cognitive profiling and can help clinicians, educators, and care teams gather clearer data for decision-making. If you'd like to discuss fit for your setting, visit the website or reach out through their contact options.

Orange Neurosciences' Cognitive Skills Assessments (CSA) are intended as an aid for assessing the cognitive well-being of an individual. In a clinical setting, the CSA results (when interpreted by a qualified healthcare provider) may be used as an aid in determining whether further cognitive evaluation is needed. Orange Neurosciences' brain training programs are designed to promote and encourage overall cognitive health. Orange Neurosciences does not offer any medical diagnosis or treatment of any medical disease or condition. Orange Neurosciences products may also be used for research purposes for any range of cognition-related assessments. If used for research purposes, all use of the product must comply with the appropriate human subjects' procedures as they exist within the researcher's institution and will be the researcher's responsibility. All such human subject protections shall be under the provisions of all applicable sections of the Code of Federal Regulations.



© 2026 by Orange Neurosciences Corporation